A tévhittel ellentétben, a tartalmi optimalizáláson és a linképítésen túlmutat a SEO munka sava-borsa. A cikk olyan technikai jellegű, SEO problémákat mutat be, amelyekre (az esetek többségében) nem is számítunk.
Nem mobilbarát oldal
A mobil eszközökről (smartphone és tablet) érkező látogatók száma évek óta emelkedik, a Google Analytics-ben mért adatok alapján az az észrevételem, hogy ez különösen igaz az organikus forgalomra, ami nem ritkán a 35%-ot is meghaladja. Ennek természetesen a keresőmotorok fejlesztői is tudatában vannak, így a piac/felhasználók igényeihez igazodva alakítják a jövőbeli oldalakat értékelő irányelveket és algoritmusokat, nem beszélve egy több szakmai fórumon is kilátásba helyezett Mobil frissitésről. Ezt hivatott alátámasztani a Google Developer közpotban közzétett Mobil-Friendly Test tool, mely segítségével megvizsgálhatjuk, hogy oldalunk a Google szemében mobilbarát, avagy sem.
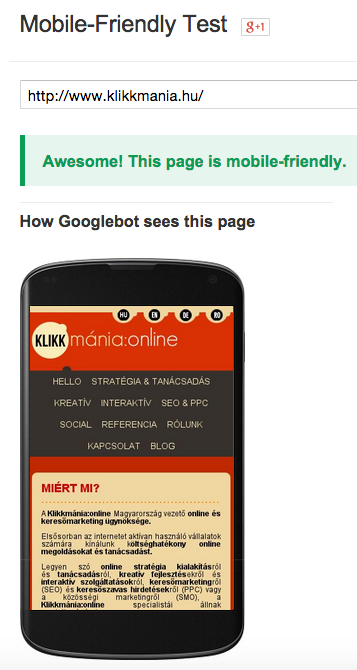
UPDATE: A jóslatunk időközben beteljesülni látszódik, a Google a hivatalos oldalukon közzétette, hogy a mobilbarát weboldal hamarosan a rangsorolás része lesz.
Duplikált tartalom
Az egyik legáltalánosabb hiba (amellyel kisebb oldalaknál éppúgy találkozom, mint a nagyoknál), hogy jóhiszemű tudatlanságból, vagy technikai hibából adódóan duplikálódik az oldal tartalma. Ezek a leggyakoribb esetek:
Jóhiszemű tartalomsokszorozás
Az egyik lehetőség, hogy az adott oldal tulajdonosa egy-egy tartalmat felajánl vagy továbbad más oldalaknak is (például egy sajtóközlemény, vagy egy ismeretterjesztő anyag). Ez visszafelé is igaz, amikor egy adott tartalmat úgy hoz le az oldal, hogy a tartalom végén jelölik a forrást szövegesen, esetleg link is mutat a forrás oldalára (ez ritkább).
Megoldás: Ebben az esetben (a Google irányelve szerint) az elfogadható eljárás a HTML-be rejtett “canonical” jelölés, amely azt hivatott közvetíteni a Google botjának, honnan is kölcsönözte az oldal eredetileg a szöveget.
Ebben az esetben a következő kódot kell az oldal HTML kódjába illeszteni:
< link rel=”canonical” href=”http://www.pelda.hu/valami”>
Redundáns domainek
A rosszul beállított URL rendszer miatt főhet a fejünk egy Panda frissítés után. Igen gyakran szembesülök azzal malőrrel, hogy az oldal redudáns domainek alatt fut, azaz elérhető a tartalom www-vel vagy www nélkül, /jellel és nélkül a link végén, illetve ecommerce oldalakon a különböző szűrések is próbára teszik az avatatlanabb webmestereket.
Megoldás: Válasszuk ki és állítsuk be szerver szinten a használatos URL verziót, illetve a Google Webmaster Tools-ban is javasolt hozzáadni mind a két verzióját az oldalnak és manuálisan kiválasztani a végleges változatot.
Dinamikus URL-ek
A filterek és egyéb paraméterek miatt miatt létrejövő dinamikus URL-ek szép számmal gyarapíthatják az URL-ek számát, egyenesen arányosan növelve a duplikált oldalakat is.
Megoldás: Az általános paraméterek kizárására a Google Webmester központban nyílik lehetőségünk (az URL-paraméter menüpont alatt, az adott paraméter hozzáadásával), ám – ahogy a Google is jelzi – ez haladó szintű tudást igényel, magunktól ne zárjunk ki semmilyen paramétert! Szintén megoldást nyújthat a “rel canonical” jelölés.
Carbon copyzott oldalak
Bár ez a legritkább eset, de szintén lehet találkozni különböző domaineken létrehozott, gyakorlatilag klón oldalakkal, amelyeken 99%-ban megegyezik a tartalom.
Megoldás: A 301-es átirányítás mellett működőképes lehet a “cross-domain canonical“, tehát az indexelni kívánt oldalra linkelni az összes, duplikációt okozó domainről.
Oldalsebesség
A szintén felhasználói élményt javító szempontot komolyan veszik a Google mérnökei: joggal várják el a weboldalak üzemeltetőitől, hogy megtegyék azokat a technika lépéseket, amelyek betartásával a Google is jobb szívvel ajánlja majd az oldalt, a látogatók pedig nagyobb valószínűséggel maradnak tovább, ill. térnek vissza később.
Erre is ad segítséget a Google Developer center: a PageSpeed Insights az egyik legjobb online eszköz a témában, segítségével részletes technikai elemzést kapunk oldalunk jelenlegi sebességégéről, és a sebességet befolyásoló hibáiról. Az eszköz külön elemezi az oldal desktop és mobil sebességének jellemzőt, illetve a mobilos használhatóságot is (UX). Az oldalsebesség fontosságáról korábban is esett már szó, érdemes elolvasni A mobilbarát weboldalt segítő webmester eszköz című cikkünket is.
URL struktúra
Az URL struktúra kialakítása az egyik legfontosabb kérdés egy weboldal megtervezésénél, hiszen a domainben szereplő kulcsszavak nem csak az oldal rangsorolásánál játszanak fontos szerepet: a találati listán megjelenő információ 20%-át ez a tartalom tölti ki!
Egy új weboldal létrehozásánál a lehető legritkább esetben gondolnak időben a SEO szempontokra, illetve a szakvélemény kérésére, ezért (a weboldallal kapcsolatos kötségeit sokszorozva) a folyamatok végén történik a SEO tanácsadás és ezek implementálása, így a tervezett büdzsé mellett vismajorként jelenik meg az utólagos fejlesztések számlájára. Gyakori hiba a rosszul felépített, nem következetes URL rendszer is, ahová felesleges kategóriákat generálnak, vagy éppen a legfontosabbakat hagyják ki.
Szintén fontos figyelembe venni a szerverről érkező státuszkódok alakulását. A hibát jelző kódokat a Google Webmsetereszközök felületén ellenőrizhetjük a legegyszerűbben. Ha minden rendben van az oldalunkkal, akkor 200-as státuszkódot küld az oldalunk, ezzel nincs semmilyen teendőnk. Azonban biztosra veszem, hogy ezzel ellentétben mindenki találkozott már a 404-es hibaüzenettel.
Mikroadatok használata
A technikailag felkészültebb, nagyobb oldalak már régóta használják a strukturált adatokat, ám az korántsem biztos, hogy minden stratégiailag fontos jelölést is alkalmaznak, pedig ezek a könnyen implementálható elemek nem csak a keresőmotoroknak segítenek az adatok értelmezésében, hanem a találati listán is segítenek kiemelni az oldalt.
Gondoljunk csak a filmértékelő oldalakra (mint az imbd.com vagy a rottentomatoes.com), ahol az oldal felhasználóinak értékelése megjelenik a találati listán egy 0-5-ig terjedő csillagos értékelési felületen keresztül.
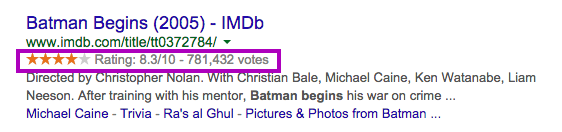
De nem kell ilyen messzire mennünk, gondoljunk csak a receptes oldalakon az ételek elkészítési idejére vagy a nehézségi szintre. Ezeket mind megadhatjuk és mikroadatokkal jelölhetjük, hogy a látogató figyelmét a találati listán felkeltve az oldalunkra irányítsuk.
Rossz belső navigáció, belső linkeltség, sitewide linkek
A megfelelő belső linkeltség kialakítása szintén igényel némi rutint és tervezést. Tapasztalataim szerint még mindig rengetegen helyeznek el a footerben belső aloldalakra mutató linkeket, ezzel sitewide linkeket generálva. Ezzel nem is lenne nagyobb probléma, ha a felhasználó számára láthatatlan, ám a keresőmotoroknak nagyon is beszédes, technikai jelöléseket is implementálnák. Itt a nofollow attribútum alkalmazására gondolok, aminek használata igen egyszerű, és segítségével kommunikálni tudjuk, hogy mely linkeket vegyen figyelembe a crawler program, és mely linkeket ne kövessen. Így irányíthatjuk tudatosan az oldalak SEO értékének “átadódását”, ezzel növelve a találati listán történő előkelőbb helyezésünket.
A “nofollow” attribútum kódja:
<a href=”signin.php” rel=”nofollow”>bejelentkezés</a>
Másik fontos elem a belső linkeltség rendszere. Itt gondoljunk akár a fent említett technikai SEO értékek irányítására, akár a látogatóink oldalon belüli terelgetésére. Ha egy blogcikkünk vonzotta oldalunkra a látogatót, akkor érdemes további, kapcsolódó bejegyzésekre irányítani, növelve így az oldalunkon töltött időt és az esélyt, hogy akár feliratkozóként, akár vevőként konvertáljon.
Breadcrumb
Szintén hasznos az ún. breadcrumb – azaz kenyérmorzsa – navigációs linkek implementálása. Ezek segítségével nem csak a látogatóknak könnyíti meg az oldal belüli szint meghatározását és az adott szint fölötti kategóriákra való visszatérését, hanem a keresőrobotoknak is segítenek megérteni a hierarchiát, illetve az adott oldalra vonatkozó kulcsszó-kiemelést.
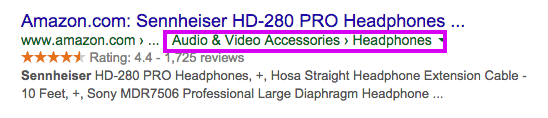
Ezek mellett a keresők találati lista oldalán (SERP) is visszaköszönhet, mint bővített kivonat, ha ellátjuk a megfelelő mikroformátum jelöléssel!
Robots.txt
Bár egyre ritkábban, de találkozom olyan oldalakkal, melyekről hiányzik a robots.txt file. Ez a legegyszerűbb módja annak, hogy a keresőrobotokat kizárjuk azokról az oldalakról, directorykból és subdoaminekről, melyeket nem szeretnénk az indexelt oldalak között látni. A robots.txt fájl hiánya miatt például kellemetlen lehet, ha a fejlesztés alatt álló oldalunk kerül be az indexbe, főleg akkor, ha már felkerült a tartalom egy része is. Így a tudtunk nélkül kaphatunk büntetést, amely adott esetben azt is jelentheti, hogy több oldallal hátrébb kerülünk a találati listán egy olyan kulcsszóra, amellyel korábban stabilan az első oldalon az első három pozícióban szerepeltünk.
User-agent: *
A legegyszerűbb elemei a robots.txt fájlnak a user-agent, amely a keresőmotorokat jelöli. Ezeket külön-külön is megadhatjuk (akár keresőmotorokra szabva), de alapesetben elég az összesre érvényes hivatkozást megadni, ezt csillag szimbólummal jelölik.
Allow: /
Az engedélyezett oldalakat az “Allow” parancs jelöli (a teljes tartalomra vonatkoztatva), a kivételnek szánt URI-ket ez után zárják ki, per jellel zárva a domain végét.
Tehát ha csupán az “Allow” parancsot adjuk meg, és ez után nem zárunk ki semmit, akkor ezzel az összes oldalunk és aloldalunk feltérképezését engedélyezzük!
Disallow: /admin
Disallow: /felhasznalok/
A kizárni kívánt alkönyvtárakat a “Disallow” parancs jelzi, itt ha több alkönyvtárat is ki szeretnénk zárni, akkor -, akkor egyesével kell kizárnunk ezeket (például az admin és a user belépési felületét).
Disallow: /
Abban az esetben, ha a teljes oldalra vonatkoztatjuk a robotok tiltását (például a tesztfázisban lévő oldalakat), akkor az “Allow” parancshoz hasonlatosan a teljes oldalt kell kijelölnünk, alkönyvtár megadása nélkül.
Ezen kívül természetesen még rengeteg cizellált parancs létezik, ezeknek a meghatározása és beállítása minden oldalnál egyedi vizsgálatot igényel, melyhez mindenképpen kérjük ki egy SEO szakember véleményét!
Elrettentő példaként olvastam olyan esetről, amikor egy banknak a newsletter oldala és ahhoz tatozó adatok (e-mail címek) nem voltak külön titkosítva és a robots fájlban sem voltak kizárva, így az összes e-mail cím az indexbe került. Természetesen itt nem a robots file az elsődleges védelmi vonal, ennél sokkal komolyabb munkát igényel a titkosítás.
Google Webmestereszközök
Az Analytics mellett az egyik leghasznosabb eszköze a Google-nek, mégis meglepően sokan nem állítják be, vagy nem is tudnak a létezéséről. Pedig kéne. Gyakorlatilag ez a legfőbb információs csatorna a webmesterek és a Google között, ahol értesítést kapunk az oldalunkkal kapcsolatos kritikus hibákról (például nem mobil barát), vagy arról, ha esetleg büntetést kaptunk.
A Webmestereszközök fontos kiegészítője a Google Analytics-nek, hiszen rengeteg adatot szerezhetünk oldalunkról, többek között az indexelt oldalak számát, a feltérképezési és szerverkapcsolati hibákat, a 404-es, illetve az egyéb, rossz státuszkóddal bíró oldalak számát.
A technikai adatok mellett oldalunk tartalmi állapotáról is kaphatunk hasznos információkat, úgy mint a leggyakoribb tartalmi kulcsszavak vagy a belső linkeltség. Az üzeneteken és statisztikákon kívül operatív teendőket is kiszolgál az oldal, többek között itt küldhetjük a Google indexébe az általunk javasolt legfontosabb oldalakat tartalmazó sitemapet, eltávolíthatjuk a károsnak ítélt linkeket, tesztelhetjük a robots.txt fájl működését, illetve az URL struktúránkat sértő paramétereket is kizárhatjuk.
Az oldal összekötése a Google eszközökkel
Triviálisnak tűnhet, ám meg kell említenem a Google eszközök és weblapunk összekötését. Önmagában nem elég külön-külön létrehozni Google Analytics és Google Webmaster profilokat, fontos ezeket összekötni, így teljesebb képet kaphatunk a fiókunkról.
Ennek lépései:
1. A Google Webmestereszközök felületén a főoldalon maradva válasszuk ki a “Webhely kezelése” gombot, majd a legördülő sávból klikkeljünk a “Google Analytics tulajdon” linkre!
2. Válasszuk ki a társítani kívánt oldalt és kattintsunk a Mentés gombra: https://support.google.com/webmasters/answer/1120006?hl=hu&utm_id=ad
Ide sorolható még a Google Business Plus oldal verifikációja, azaz a tulajdonának visszaigazolása is. A legegyszerűbb és legkézenfekvőbb megoldás, ha megelőzi a Webmestereszközökben való igazolása az oldal tulajdonnak, hiszen – ugyanabból a Google fiókból kezelve – automatikusan igazoljuk az Üzleti oldalt is.
A technikai SEO hibák újabb fajtáit naponta fedezik fel a seológosuk az optimalizálás mély és sötét dzsungelében, ezért itt tényleg csak a leggyakoribb és legjellemzőbb eseteket soroltam fel. A témával kapcsolatban felmerülő kérdésekre természetesen szívesen válaszolok komment formájában, amennyiben részletesebb elemzésre van szükségük, úgy ezen oldalon vehetik fel velünk a kapcsolatot.
